
A research team from South Korea has conducted an extensive search on the Tor network to obtain a dataset suitable for training large language models (LLMs). The data was sourced exclusively from the darknet, which may include individuals such as hackers, cybercriminals, and fraudsters, as well as those who are politically persecuted or require anonymity for various reasons, including opaque business practices or unsupervised information exchange under a repressive regime.
The DarkBERT model has been developed utilizing this category of training data and, with regards to its abilities, it has been deemed to be "equivalent or marginally superior" to other Large Language Models (LLM) that share the same architecture type (BERT and RoBERTa). These findings have been reported by the team in a preliminary research report on arXiv.org. It is advisable to refrain from entrusting it with atomic code or any confidential information, although this cautionary measure is applicable to generative AI systems in general.
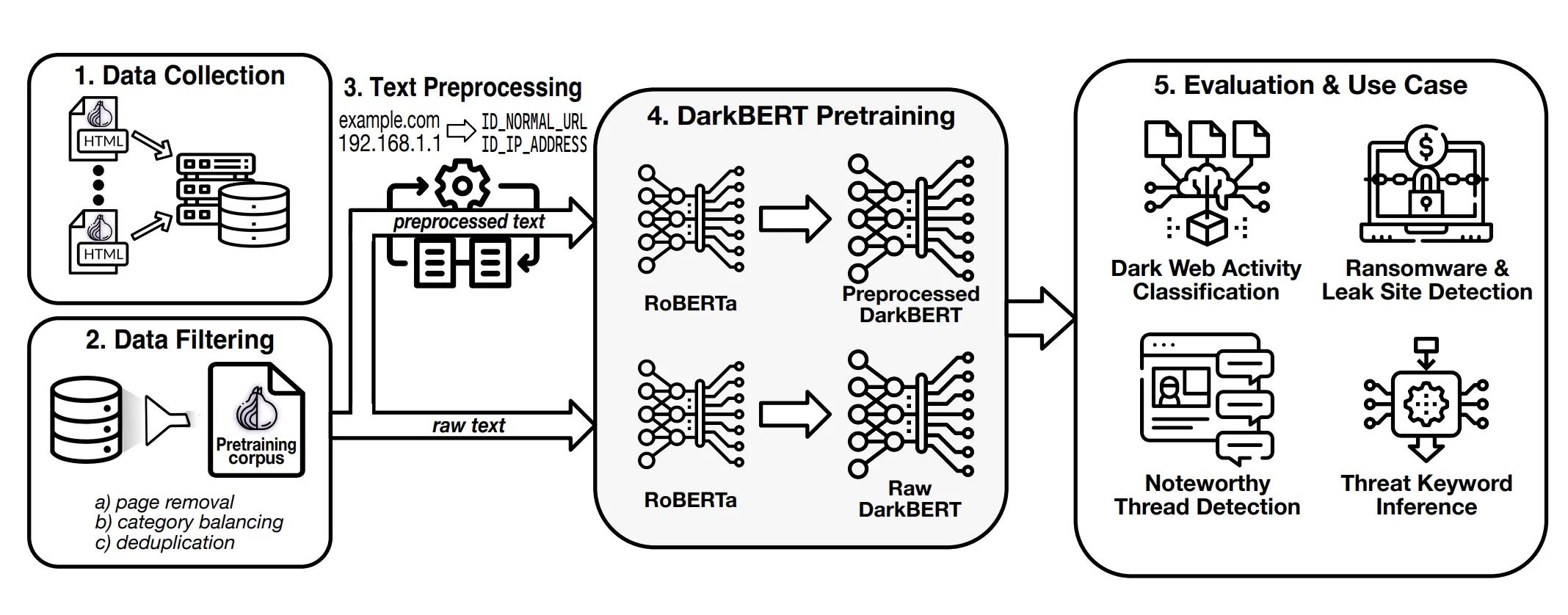
A significant challenge in the development of a pre-trained language model (PLM) lies in obtaining the appropriate training corpus. The acquisition of data from the dark web can prove to be particularly arduous; however, S2W's collection capabilities enabled them to amass a substantial collection of dark web text. Their prior research on dark web language revealed that certain portions of the data may not be suitable for training purposes. Consequently, they undertook measures to filter the corpus by eliminating low-information pages, balancing it according to category, and removing duplicate pages. Additionally, they employed preprocessing techniques to anonymize common identifiers and potentially sensitive information. Ultimately, they obtained an unprocessed corpus of 5.83 GB and a processed corpus of 5.20 GB.
Statement from creators of DarkBERT
As per the declarations made by the creators of DarkBERT, they have no inclination towards seizing global dominance or transferring content from the concealed internet to the observable realm of the internet (Clear Web). However, they have bestowed a somber connotation to their creation by christening it as such. The objective behind DarkBERT is to explore the merits and demerits of a domain-specific model for the Deep Web in diverse usage scenarios.
Conclusion
The preface of the report outlines the objective of the research, which is to expand the language of the Darknet. The development of language models tailored to the dark web is deemed to be of significant value, as it could yield valuable insights. The South Korean team recognizes the importance of accurately representing the darknet in a comprehensive language model, in order to address the lexical and structural diversity that sets it apart from the visible realm of the clear web. The researchers aim to conduct security research and create an AI model that possesses contextual understanding of the Darknet domain.